
Building a RAG Plugin for Obsidian Notes Using Google's File Store API
I spent the weekend building a plugin for Obsidian Notes on top of Google's new Gemini API File Search Tool and wanted to share what I learned along the way. You can check out the full implementation at github.com/benbjurstrom/ezrag.
As a little backgroud, I've been searching for a simple way to give Claude Desktop the ability to semantically search my Obsidian vaults. As of this writing I haven't found any solutions that just work without a lot of fiddling. So when Google announced their new API I decided to take a shot at building my own solution.
#How the File Store API Works
The basic flow is straightforward. First, you upload your documents to a Gemini File Search store along with some metadata.
1const client = new GoogleGenerativeAI(apiKey); 2 3// Upload a document 4await client.uploadFileToFileSearchStore({ 5 storeName: "my-notes-store", 6 file: new Blob([fileContent], { type: "text/plain" }), 7 displayName: "My Note.md", 8 metadata: { 9 path: "My Note.md",10 contentHash: "sha256hash..."11 }12});Then when you want to query your notes, you configure the Gemini model to use the File Search tool:
1const model = client.getGenerativeModel({ 2 model: "gemini-2.5-flash-latest", 3 tools: [ 4 { 5 fileSearchTool: { 6 fileSearchStores: ["my-notes-store"] 7 } 8 } 9 ]10});11 12const result = await model.generateContent("What Python packages can convert PDF to markdown?");13const metadata = result.response.candidates[0].groundingMetadata;This means that you don't query the vector store directly. Instead, Gemini handles the semantic search internally and returns a standard chat response along with a groundingMetadata object that tells you exactly which chunks from which documents supported each part of the answer.
#Understanding the Grounding Metadata
To understand how the Grounding Metadata works, let's take a look at an real message I sent via the plugin's chat interface. In the screenshot below, I asked gemini-2.5-flash to search my notes for information about a python package for converting PDFs to markdown. And as you can see the response in the UI contains citations to the specific notes that the model used.
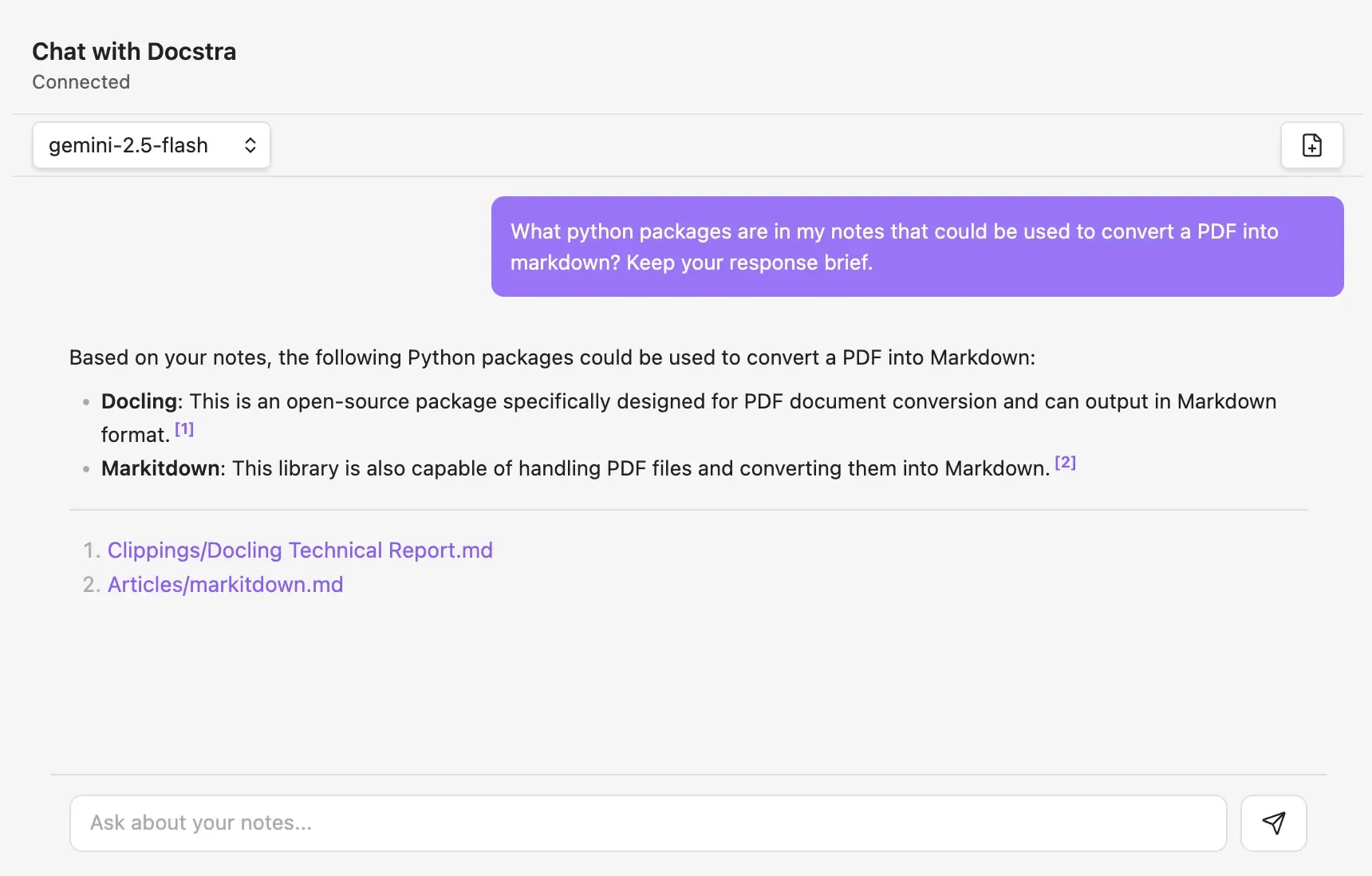
To give you a sense of how this UI is built, let me show you what the raw API response looked like for the message above. I'm including the full response here because I haven't seen this readily documented anywhere else. I've shortened some parts for clarity but kept the structure intact:
1{ 2 "candidates": [ 3 { 4 "content": { 5 "parts": [ 6 { 7 "text": "Based on your notes, the following Python packages could be used to convert a PDF into Markdown:\n\n* **Docling**: This is an open-source package specifically designed for PDF document conversion and can output in Markdown format.\n* **Markitdown**: This library is also capable of handling PDF files and converting them into Markdown." 8 } 9 ]10 },11 "groundingMetadata": {12 "groundingChunks": [13 {14 "retrievedContext": {15 "title": "Clippings/Docling Technical Report.md",16 "text": "{CHUNK_TEXT}"17 }18 },19 {20 "retrievedContext": {21 "title": "Articles/markitdown.md",22 "text": "{CHUNK_TEXT}"23 }24 }25 ],26 "groundingSupports": [27 {28 "segment": {29 "startIndex": 98,30 "endIndex": 230,31 "text": "* **Docling**: This is an open-source package specifically designed for PDF document conversion and can output in Markdown format."32 },33 "groundingChunkIndices": [34 035 ]36 },37 {38 "segment": {39 "startIndex": 231,40 "endIndex": 336,41 "text": "* **Markitdown**: This library is also capable of handling PDF files and converting them into Markdown."42 },43 "groundingChunkIndices": [44 145 ]46 }47 ]48 }49 }50 ]51}As you can see the model's answer lives in candidates.content.parts.text like any normal chat response. But because we enabled the File Search tool, we also get groundingMetadata.
The groundingChunks array contains all the document chunks the model referenced. Each chunk includes the raw text and a title field that corresponds to the displayName provided during upload.
The groundingSupports array maps specific parts of the answer to their source chunks. Each segment has startIndex and endIndex pointing to character positions in the response text, plus groundingChunkIndices that reference the chunks array.
This structure lets you build precise citations. You know exactly which sentence came from which document.
#Summing It all up
#The Good: It Just Works
The File Store API achieves exactly what I was after. With nothing more than an API key, you get semantic search over your entire Obsidian vault that actually understands what you're asking. Based on my usage so far, the search quality is excellent. It consistently finds the relevant notes even when you phrase questions differently than how you wrote them.
The indexing is also remarkably fast. Updates are searchable within seconds, and there's no waiting around for processing queues or rate limits.
#The Bad: SDK Bug Breaks Citations
There's a critical bug in Google's TypeScript SDK that drops the displayName parameter. This breaks the entire citation system because you need that title field in the groundingChunks to know which document was cited.
Since my citation system depends on getting the Obsidian file path back in the title field, this bug essentially broke everything. I ended up monkey-patching the SDK at runtime to inject the missing parameter.
#The Ugly: No Metadata Queries
Here's the real limitation: there's no way to query documents by metadata. Gemini assigns random identifiers to your documents, and you can't search for them by the metadata you attached.
Want to check if a document with a specific file path already exists? You have to page through your entire collection using fileSearchStores.documents.list. The kicker? You can only fetch 20 documents at a time.
I solved this by building a local index in localStorage that maps file paths to document IDs and content hashes. When files change, the plugin checks hashes locally instead of calling the API. If the local index gets out of sync (cleared storage, switched devices), a smart reconciliation system matches documents by hash to restore state without creating duplicates.